

9 月 4 日,微软在美国中南部地区的圣安东尼奥数据中心由于雷电天气影响导致电压激增,数据中心的冷却系统发生故障。为保证数据和硬件完整性,数据中心的自动化措施强制关闭了系统电源以防止机器因过热造成损坏。这一事故引发了 Azure 中断,Office 365 以及 Azure Active Directory 服务都受到影响,并且恢复相关存储服务经历了很长时间。
故障从 9 月 4 日上午 9 点(北京时间 9 月 4 日 17:00)左右开始出现问题,到 9 月 5 日 13 点左右(北京时间 9 月 5 日 21:00 左右),微软大多数受影响服务的存储可用性已经恢复,整个故障中断时间超过 24 小时。

跟踪服务中断的 DownDetector.com 网站显示 Azure 服务中断主要位于德克萨斯州:
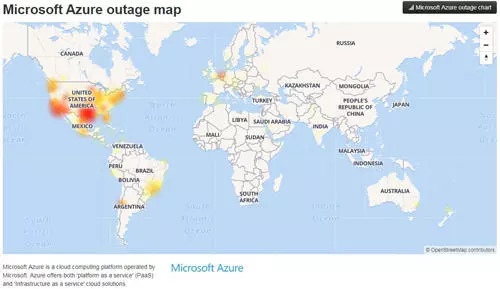
Azure 官方推特 Azure Support 让用户查看 Azure 状态页面,但是 Azure 服务中断甚至影响到该页面也一度无法访问。Azure Support 将事故称为“网络问题”,并表示中断只会影响美国中南部的客户,但是很多用户表示中断已经影响了包括西欧、亚洲在内的其他地区。
Azure Support 在对用户的回复中澄清了为什么其他地区会受到影响:“在某种程度上,我们所有的数据中心都是相互联系的。因此,如果一个数据中心出现故障,它将转移到其他数据中心。此外,在欧洲的客户可能会在受影响的数据中心托管一些资源。“
包括 Office 365 和 VSTS (Visual Studio Team Services)在内的近 40 个 Azure 服务受到影响。根据 Office 365 的公告,Office 365 用户遇到的问题类型如下:
- Exchange – 某些用户可能无法访问网页上的 Outlook。 通过其他协议进行的电子邮件访问则有可能不受影响。
- Power BI – 用户可能收到“服务器不可用”错误或可能无法登录。
- SharePoint – 大多数影响已得到缓解,但一部分用户可能无法进行更改或更改无法保存。
- Microsoft Teams – 用户可能无法访问 Teams 的 Office 文档。
- Intune – 受影响的用户可能无法访问 Intune 门户或其他功能。
根据 VSTS 的公告,这次中断影响了使用微软 Visual Studio Team Services 的开发人员,导致他们无法访问帐户,报告仪表板也无法加载。
根据 Microsoft Dynamics 公告,这次中断还影响了 Azure Active Directory,Microsoft Dynamics Finance 以及 Operations 和 Lifecycle Services 的用户。
9 月 5 日,Azure 状态更新中表示,工程师正在优先恢复存储资源,以便恢复依赖于这些受影响资源的所有服务,但是恢复过程需要一段时间。到北京时间 9 月 5 日晚 9 点左右,大多数受影响的服务已经恢复。
到底应该怎么上云?
此次 Azure 服务中断时间长,影响较大,又引发了大家对上云风险的讨论。
VSTS 一整天都用不了,这是个很严重的问题。有用户说:
我无法相信 Azure 仍在瘫痪。昨天整天我都无法访问美国中南部地区的资源。整个区域的服务中断可能会持续 24 小时的事实将使我的团队认真考虑转向 AWS。如果我们的服务中断 5 分钟,我们的客户会很生气。我甚至不想去想如果因为一些完全不受我们控制的事情而宕机一整天会发生什么。
讨论中也有这样的疑惑:
区域性中断应该不会拖垮那么多服务,地理冗余在哪里?
虽然很多细节都围绕在具体是哪里的冷却系统发生了故障,Azure 这次的服务中断可以让大家认识到可用区(AZ,availability zones) 的重要性。AZ 能让使用云服务的用户在给定云计算区域内的几个独立建筑周围分散工作量,以期避免单个数据中心会带来的问题。
AZ 的设置直到去年才成为微软基础设施战略的一部分,并且目前微软只向全球 54 个区域中的三个地区推出了 AZ(美国东部 2 区和东南亚地区可作为预览)。
上云本来是要防止这些基础设施问题的,但是不要忘了,即使 99%的 SLA 也意味着一年 365 天大约可以有 4 天不在线。所以很多公司会提到 99.9% 和 99.99%,当以年为单位来看,小数点后面的位数也不可小觑。公有云提供的高度冗余意味着公司需要在全国各地拥有为站点提供服务并充当备份的私有数据中心。很多公司连建立这么多数据中心的预算足都不足,更不用说额外的维护成本了。
Mimecast 的网络弹性专家 Pete Banham 说:“今天在 Azure 发生的事件再次提醒企业需要建立自己的冗余,而不是依靠单一的供应商。所有公司(包括 Microsoft)都需要考虑由于技术故障或人为错误而导致关键服务故障可能产生的下游影响。服务总是会有失败的时候,IT 领导者们需要确保自己没有将责任外包给单一的云服务。”
主题测试文章,只做测试使用。发布者:云大使,转转请注明出处:https://www.xp8.net/web/1593.html
 微信扫一扫
微信扫一扫 
