腾讯云云数据库智能参数优化设置
背景 “深度学习”这个词已经进入了公众的视线。时至今日,相关技术也比较成熟,腾讯云数据库团队也在思考如何借助深度学习的方式来提升数据库的运行效率。首先想到的就是数据库的参数调优。由于业务系统的千差万别,也无法像优化 SQL 一样在细粒度下进...
背景 “深度学习”这个词已经进入了公众的视线。时至今日,相关技术也比较成熟,腾讯云数据库团队也在思考如何借助深度学习的方式来提升数据库的运行效率。首先想到的就是数据库的参数调优。由于业务系统的千差万别,也无法像优化 SQL 一样在细粒度下进...
数据库 MySQL 支持内网和外网两种地址类型,默认提供内网地址供您内部访问实例,如果需要使用外网访问,除了开启外网地址后,通过 Linux 或者 Windows 云服务器连接访问实例,也可通过负载均衡 CLB 开启外网服务进行访问,通过 ...

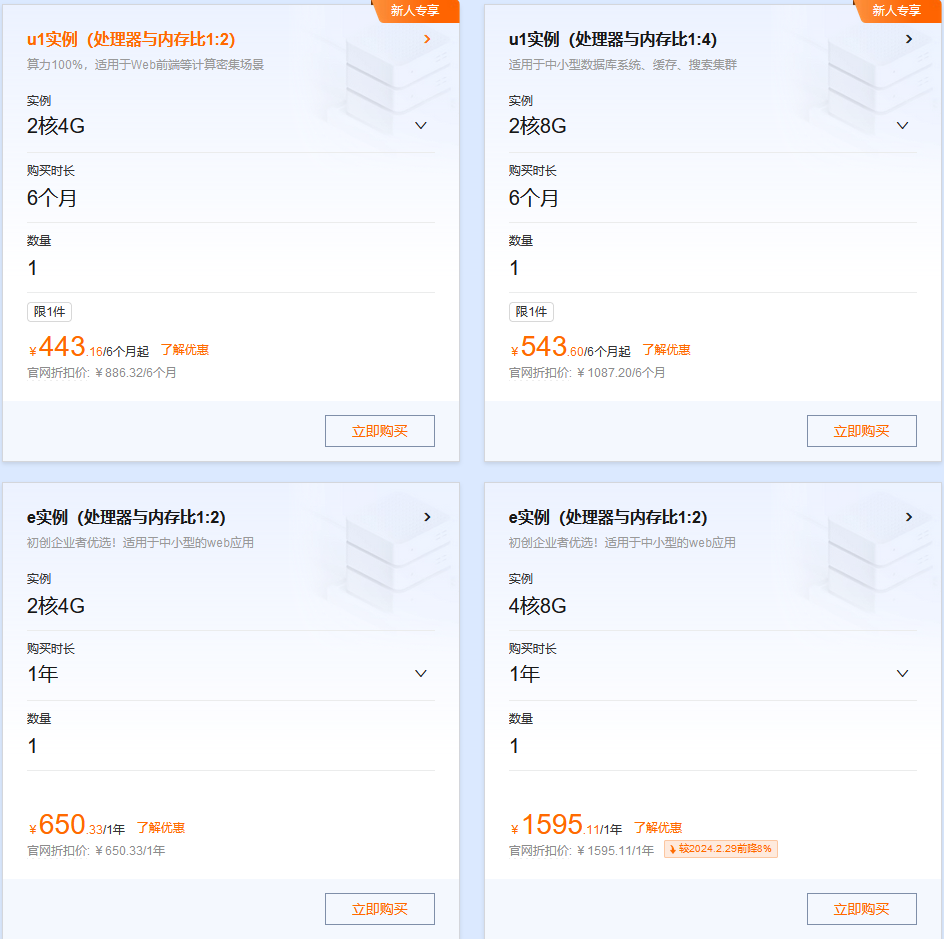
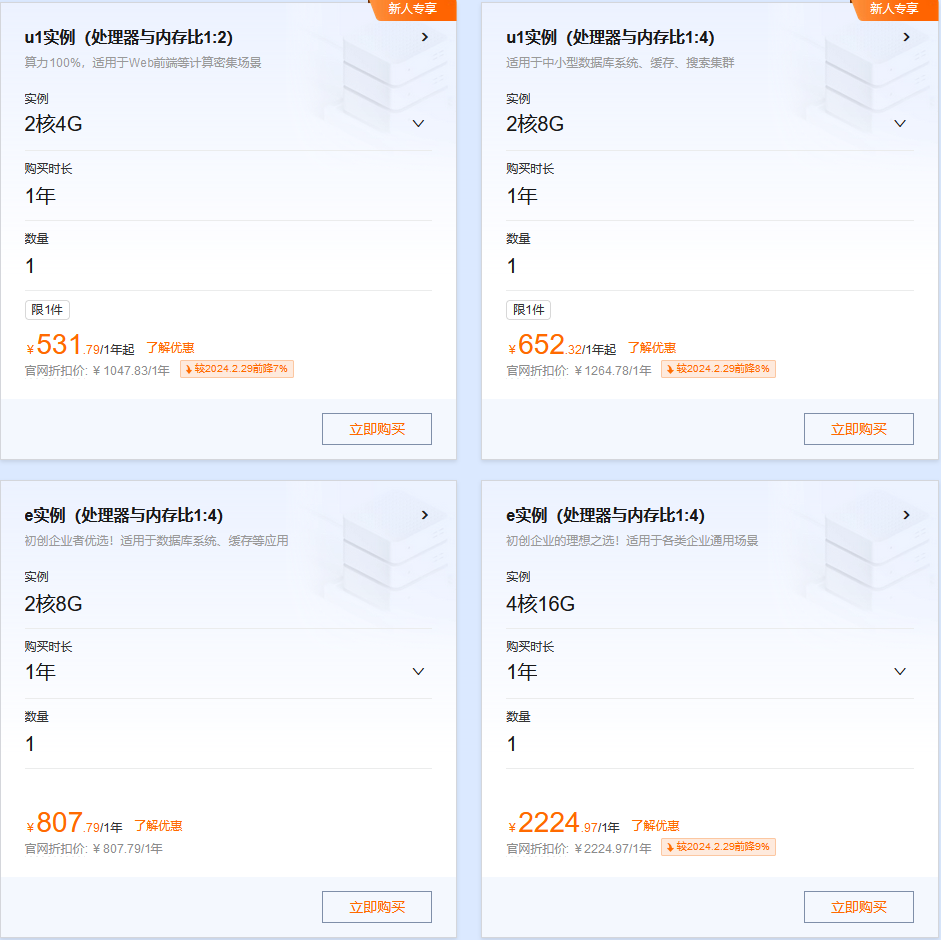
【腾讯云】3年轻量2核2G4M 低至1.7折,仅需368元!
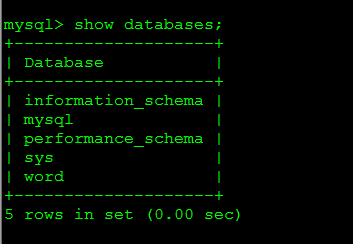
有些公司的网站负责人朋友刚接触到公司业务。对linux 还不是很熟悉 对网站的数据库无法进行备份。 今天给大家分享下 、 1.MySQL的登录命令 登录Mysql输入:mysql -u帐号 -p密码 注:密码可以之后输入 案例: mysq...

前沿 今天通过ECS对阿里云rds数据库进行导入。一直报错。 mysql: [Warning] Using a password on the command line interface can be insecure. ERROR 12...
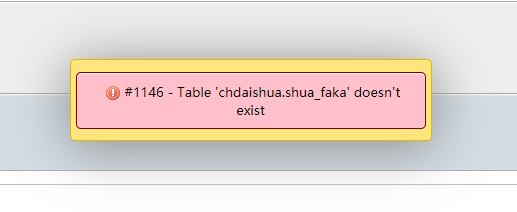
今天看到一个案例:数据库服务无法启动,也导致了不能备份数据库、所以只能使用了笨方法、直接打包DATA目录 我们的服务器是宝塔环境、 直接备份 /www/server/data 这个目录备份 下载下来 在新的服务器上安装好环境、把data...
本文主要讲述了在在linux系统下启动 mysql数据库操作,感兴趣的朋友可以了解一下。 {mysql}表示mysql的安装目录 如何启动/停止/重启MySQL 一、启动方式 1、使用 service 启动:service mysqld s...

本篇文章的主要内容是关于在mysql数据库explain中的using where和using index的使用,感兴趣的朋友可以了解一下。 1. 查看表中的所有索引 show index from modify_passwd_log; 有...
数据库中schema是数据库对象集合,它包含了表,视图等多种对象。schema就像是用户名,当访问数据表时未指明属于哪个schema,系统就会自动的加上缺省的schema 我们在学习数据库中会碰到一个模糊的概念,它就是Schema。很多人对...
最近对php查询mysql处理结果集的几个方法不太明白的地方查阅了资料,在此整理记下(相关推荐:mysql教程) Php使用mysqli_result类处理结果集有以下几种方法 fetch_all() 抓取所有的结果行并且以关联数据,数值索...
本文的主要内容是讲述在MySQL 5.7上使用group by语句出现1055错误的问题分析以及解决办法,有需要的朋友可以看一下。 1. 在5.7版本以上mysql中使用group by语句进行分组时, 如果select的字段 , 不是完全...
mysql数据库事务的隔离级别有4个,而默认的事务处理级别就是’REPEATABLE-READ’,也就是可重复读。下面本篇文章就来带大家了解一下mysql的这4种事务的隔离级别,希望对大家有所帮助。 SQL标准定义了...
为查询优化你的查询 大多数的MySQL服务器都开启了查询缓存。这是提高性最有效的方法之一,而且这是被MySQL的数据库引擎处理的。当有很多相同的查询被执行了多次的时候,这些查询结果会被放到一个缓存中,这样,后续的相同的查询就不用操作表而直接...
MySQL有多种存储引擎,MyISAM和InnoDB是其中常用的两种。这里介绍关于这两种引擎的一些基本概念(非深入介绍)。 MyISAM是MySQL的默认存储引擎,基于传统的ISAM类型,支持全文搜索,但不是事务安全的,而且不支持外键。每张...
接上一节《百万数据mysql分页问题》,我们加上查询条件: select id from news where cate = 1 order by id desc limit 500000 ,10 查询时间 20 秒 好恐怖的速度!!利用第...
Apache服务器是一个开源跨平台的web服务器。它具有多种免费且开源的web技术,适应多种操作系统。另外它还具有为软件添加更多功能的模块,使得它成为功能最丰富的HTTP网络服务器 Apache是一种流行的开源,跨平台的Web服务器,同时它...
在开发过程中我们经常会使用分页,核心技术是使用limit进行数据的读取。在使用limit进行分页的测试过程中,得到以下数据: select * from news order by id desc limit 0,10 耗时0.003秒 s...
information_schema提供了对数据库元数据、统计信息、以及有关MySQL Server的信息访问(例如:数据库名或表名,字段的数据类型和访问权限等)。information_schema库中保存的信息也可以称为MySQL的数据...
在MySQL中,RLIKE运算符用于确定字符串是否匹配正则表达式。它是REGEXP_LIKE()的同义词。 如果字符串与提供的正则表达式匹配,则结果为1,否则为0。 语法是这样的: expr RLIKE pat 其中expr是输入字符串,p...



“深度学习”这个词已经进入了公众的视线。时至今日,相关技术也比较成熟,腾讯云数据库团队也在思考如何借助深度学习的方式来提升数据库的运行效率。首先想到的就是数据库的参数调优。由于业务系统的千差万别,也无法像优化 SQL 一样在细粒度下进行针对性的调优,是令数据库管理者头痛的难题,往往需要借助经验去构筑一套相对较为优异的参数模板。数据库参数调优能力也是专家级数据库管理者的专属技能。
2019-2021年之间,腾讯云数据库团队连续发表2篇论文,分别为《Automatic Database Tuning using Deep Reinforcement Learning》和《An Online Cloud Database Hybrid Tuning System for Personalized Requirements》,并申请了国际专利。现在,基于论文将这一理论研发为一种可用的系统,在真实场景中通过调整数据库参数来提升数据库性能。
为什么需要数据库参数调优服务:
参数非常多:例如 MySQL,有几百个配置项,调优难度大。
人力成本高:需要专职 DBA,依靠专家经验,人时成本高。
工具普适性:现存工具功能有限,耗时久效果一般。
云上新需求:部分用户没有专职运维团队,参数调优很难实现。
具备一个状态为运行中的 MySQL 实例。
云盘版实例暂不支持使用智能参数调优功能。
场景智能调优每月有次数限制,每月每个实例可进行3次调优,从每月1日开始重置调优次数。
AI 智能分析每月有次数限制,每月每个实例可进行1次调优,从每月1日开始重置调优次数(AI 智能分析暂未发布,敬请期待)。
实例的 CPU 须为4核及以上,才能使用智能参数调优功能。
智能调参任务列表仅会保留最近15次的调参结果。
销毁/退还实例或实例到期时,如有智能参数调优任务处于进行中,则该任务会自动中止并删除该任务。
一个实例仅支持同时运行一个调优任务,无法发起多个调优任务。
智能参数调优功能目前暂时仅支持北京、上海、广州地域,后续将会逐步增加。
登录 MySQL 控制台,在上方选择地域,在实例列表,单击实例 ID 或操作列的管理,进入实例管理页面。在实例管理页,选择数据库管理 > 参数设置 > 智能参数调优。

在智能调优弹窗,选择场景智能调优或者AI 智能分析的参数调优方式,配置好后单击开始分析。
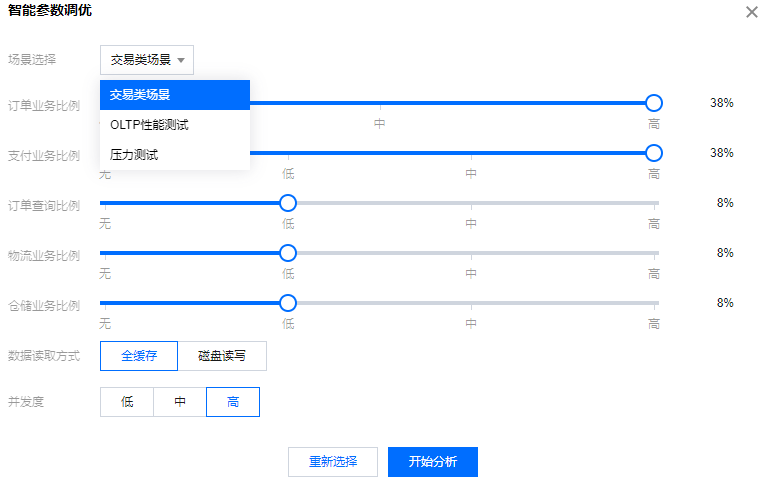
如您选择场景智能调优方式,之后步骤如下: 场景智能调优:根据选定的应用场景进行智能分析,效率更高,更具针对性。 单击场景选择下拉键选择业务场景,有三种场景(交易类场景、OLTP 性能测试、压力测试)可供选择。 选择对应场景后,您可自定义该场景下的业务占比,便于系统更精确地进行分析。配置完成后单击开始分析。
交易类场景(TPCC)
定制内容:订单业务(高)、支付业务(高)、订单查询(低)、物流业务(低)、仓储业务(低)
数据读取方式:全缓存(默认)、磁盘读写。
并发度:低、中、高(默认)。
OLTP 性能测试(Sysbench)
定制内容:读取业务比例(高),写入业务比例(默认无)
数据读取方式:全缓存(默认)、磁盘读写。
并发度:低、中、高(默认)。
压力测试(myslap)并发度:低、中、高(默认)
如您选择场景为 AI 智能分析方式(此功能暂未发布,敬请期待),之后操作步骤如下: AI 智能分析:通过对数据库运行指标进行深度分析,确定数据库业务类型,再通过深度学习算法对不同参数在确定场景下进行性能分析,并给出参数设置建议。 选择 AI 智能分析 之后,单击开始分析。
注意:
AI 智能分析功能目前正在完善中,暂未发布,敬请期待。
AI 智能分析使用了深度学习算法以及大数据分析能力,分析耗时较长,建议在业务低峰期进行。开始分析后,参数调优任务即进行中,您可在参数设置页面选择智能参数调优 > 查看任务了解任务详情。

参数调优任务结束后,在智能参数调优 > 查看任务里,单击操作列的查看结果。

确认参数调优建议后,单击应用到实例。
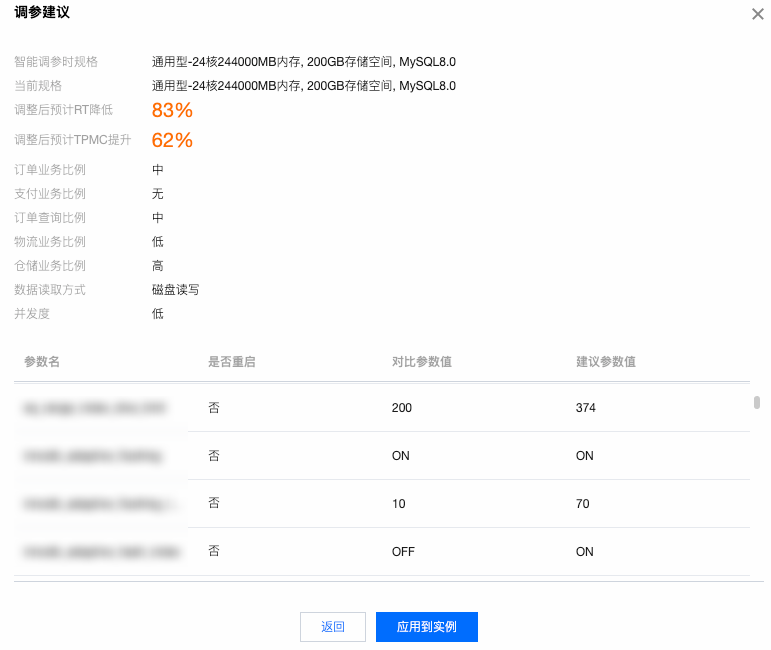
在弹窗下确认参数变更,选择执行方式,阅读并勾选重启规则,单击确定。 执行方式:
立即执行:确定后立刻应用到实例。
维护时间内:在维护时间内将此变更应用到实例,维护时间可在实例详情页修改。
购买 MySQL 实例时,您可在选定参数模板后,选择是否开启场景智能调优。使用场景智能调优后,系统会根据您选择的参数模板以及对应的业务场景进行二次调整,业务场景有三种,包括:交易类场景、OLTP 性能测试、压力测试。 对应修改结果您可以在数据库管理 > 参数设置 > 场景参数调优 > 查看任务中查看。

文档内容是否对您有帮助?
数据库 MySQL 支持内网和外网两种地址类型,默认提供内网地址供您内部访问实例,如果需要使用外网访问,除了开启外网地址后,通过 Linux 或者 Windows 云服务器连接访问实例,也可通过负载均衡 CLB 开启外网服务进行访问,通过 CLB 开启外网服务必须配置安全组规则。
以下为您介绍通过 CLB 开启外网服务,并通过 MySQL workbench 连接到实例的方法。
已申请使用后端服务功能。
1. 进入 负载均衡跨地域绑定2.0申请页。
2. 根据需要填好资料,填写完后提交申请。
3. 提交完内测申请后,提单至 CLB,申请使用后端服务功能。
说明:
如果在云数据库 MySQL 同地域已经有负载均衡实例,就可以不用购买。
进入 负载均衡购买页,选择完配置后单击立即购买。详细购买步骤可参考 购买方式。
注意:
地域需选择云数据库 MySQL 所在的地域。
仅公网 CLB 实例支持后端服务功能,因此,购买页面的网络类型选择为公网。
通过 CLB 开启外网服务的场景,仅适用于负载均衡 CLB 实例与 MySQL 实例属于同一 VPC 网络,非同一 VPC 网络暂不支持。
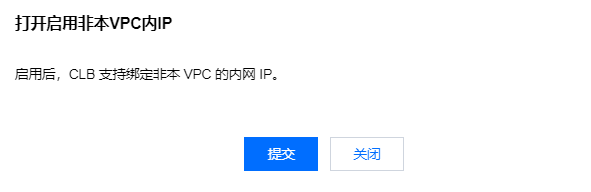
1. 启用后端服务功能(启用后 CLB 支持绑定其他内网 IP)。
1.1 登录 负载均衡控制台,选择地域,在实例管理列表,单击实例 ID,进入实例管理页面。
1.2 在基本信息页的后端服务处,单击点击配置。

1.3 在弹出的对话框,单击提交即可开启。
2. 配置外网监听端口。
2.1 登录 负载均衡控制台,选择地域,在实例管理列表,单击实例 ID,进入实例管理页面。
2.2 在实例管理页面,选择监听器管理页,在 TCP/UDP/TCP SSL/QUIC 监听器下方,单击新建。
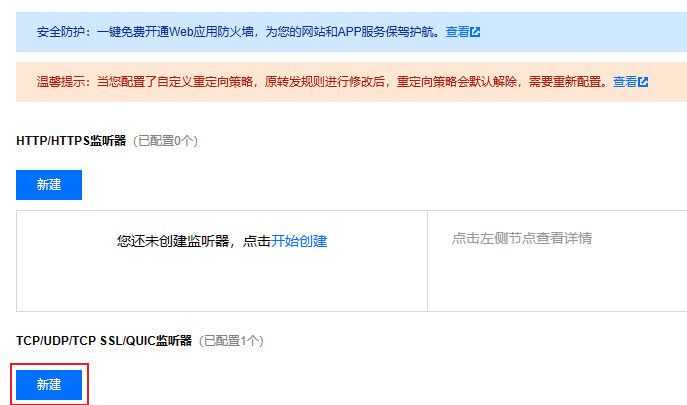
2.3 在弹出的对话框,逐步完成设置,然后单击提交即可完成创建。

1. 创建好监听器后,在监听器管理页,单击创建好的监听器,然后单击右侧出现的绑定。

2. 在弹出的对话框,选择目标类型为 IP 类型,单击添加内网 IP,输入待连接 MySQL 实例的内网 IP 地址和端口,单击确认完成绑定。
注意:
登录的账号必须是标准账号(带宽上移),如无法绑定,请 提交工单 协助处理。

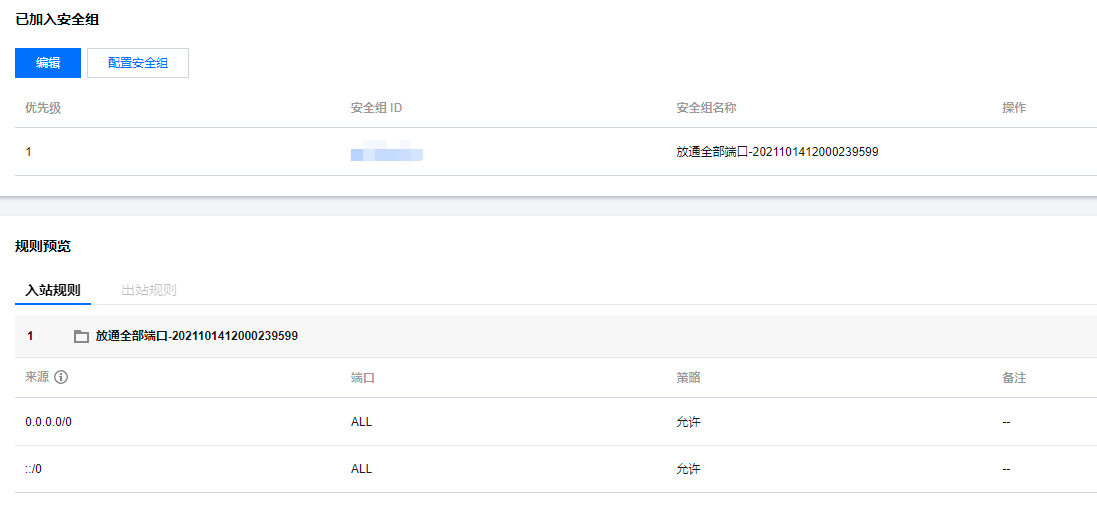
1. 登录 MySQL 控制台,选择地域,在实例列表,单击实例 ID 或操作列的管理,进入实例管理页面。
2. 在实例管理页面,选择安全组页,单击配置安全组,配置安全组规则为放通全部端口,确认安全组允许外部 IP 访问,详细配置方法请参见 配置安全组。
1. 进入 MySQL Workbench 官方下载页面。
2. 根据您的系统来选择适配版本的安装程序,单击 Download。
3. 在跳转页面中选择 No thanks, just start my download. 以快速下载。
4. 下载完成后,打开下载的安装程序,安装 MySQL Workbench。
5. 安装完成后打开 MySQL Workbench,在 MySQL Connections 后单击加号添加待连接的实例信息。

6. 在弹出的窗口下,完成如下配置后,单击 OK。

| 参数 | 说明 |
| Connection name | 为此连接命名。 |
| Connection Method | 连接方法,选择 Standard(TCP/IP)。 |
| Hostname | 输入负载均衡 CLB 实例的地址。在 CLB 实例详情页的基本信息下可查询 VIP 信息。 |
| Port | 输入负载均衡 CLB 实例的端口。在 CLB 实例详情页 > 监控器管理下可查询 TCP 端口号。 |
| Username | 输入待连接 MySQL 实例的账号名。在实例管理页 > 数据库管理 > 账号管理下创建的账号。 |
| Password | 单击 Store in Keychain,在弹窗下输入所填写的 Username 对应的密码,然后单击 OK。 |
7. 返回 MySQL Workbench 首页,单击刚创建的待连接实例信息连接到 MySQL 实例。
8. 成功连接后的界面如下所示。

网站更换服务器以后。更新网站内容上传图片遇到了问题。
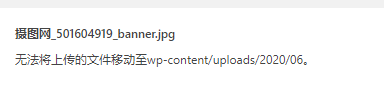
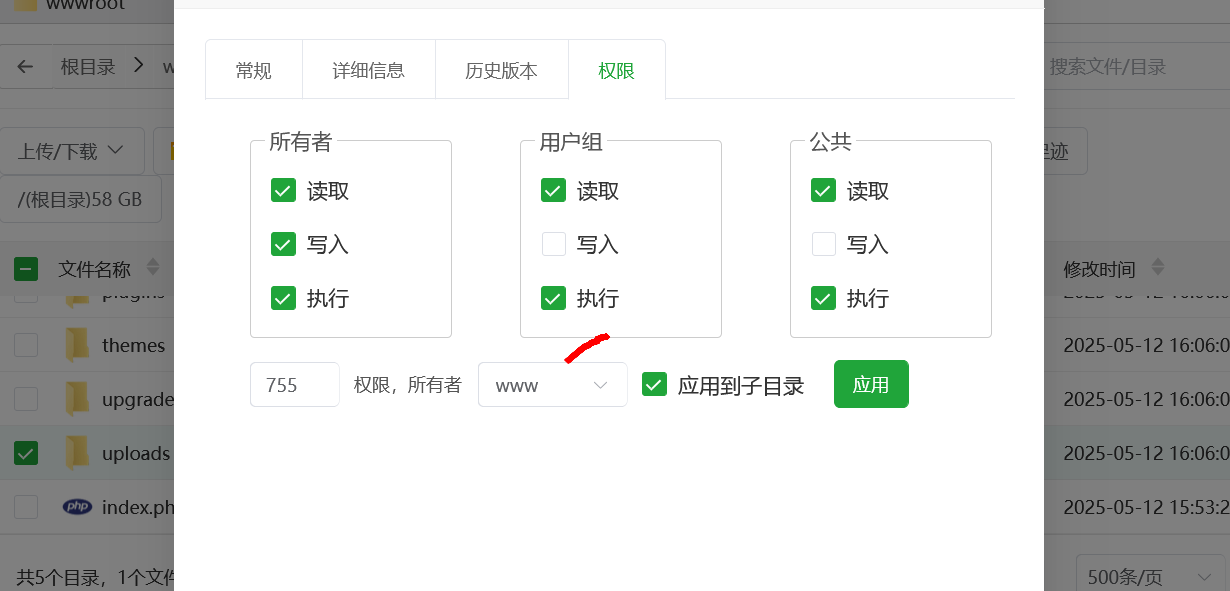
经查询是权限用户问题 。
更改wordpress或uplads的文件所有者
本地访问云服务器,或者在云服务器上访问其他网络资源时,发现网络卡顿。使用 ping 命令,发现网络存在丢包或时延较高的情况。
丢包或时延较高可能是骨干链路拥塞、链路节点故障、服务器负载高、系统设置问题等原因引起。在排除云服务器自身原因后,您可以使用 MTR 进行进一步诊断。 MTR 是一款网络诊断工具,其工具诊断出的报告可以帮助您确认网络问题的症结所在。
本文档以 Linux 和 Windows 云服务器为例,介绍如何使用 MTR 以及如何对 MTR 的报告结果进行分析。
说明
如果本地或云服务器禁用 Ping,则 MTR 将无结果。
请根据运行 MTR 的主机操作系统的不同,查看 MTR 的介绍和使用方法。
MTR:Linux 平台上诊断网络状态的工具,继承了 Ping、traceroute、nslookup 的功能,默认使用 ICMP 包测试两个节点之间的网络连接情况。
目前现有的 Linux 发行版本都预装了 MTR,如果您的 Linux 云服务器没有安装 MTR,则可以执行以下命令进行安装:
CentOS 操作系统:
yum install mtr
Ubuntu 操作系统:
sudo apt-get install mtr
-h/--help:显示帮助菜单。
-v/--version:显示 MTR 版本信息。
-r/--report:结果以报告形式输出。
-p/--split:与 --report 相对,分别列出每次跟踪的结果。
-c/--report-cycles:设置每秒发送的数据包数量,默认是10。
-s/--psize:设置数据包的大小。
-n/--no-dns:不对 IP 地址做域名解析。
-a/--address:用户设置发送数据包的 IP 地址,主要用户单一主机多个 IP 地址的场景。
-4:IPv4
-6:IPv6
以本机到 IP 为119.28.98.39的服务器为例。 执行以下命令,以报告形式输出 MTR 的诊断报告。
mtr 119.28.98.39 --report
返回类似如下信息:
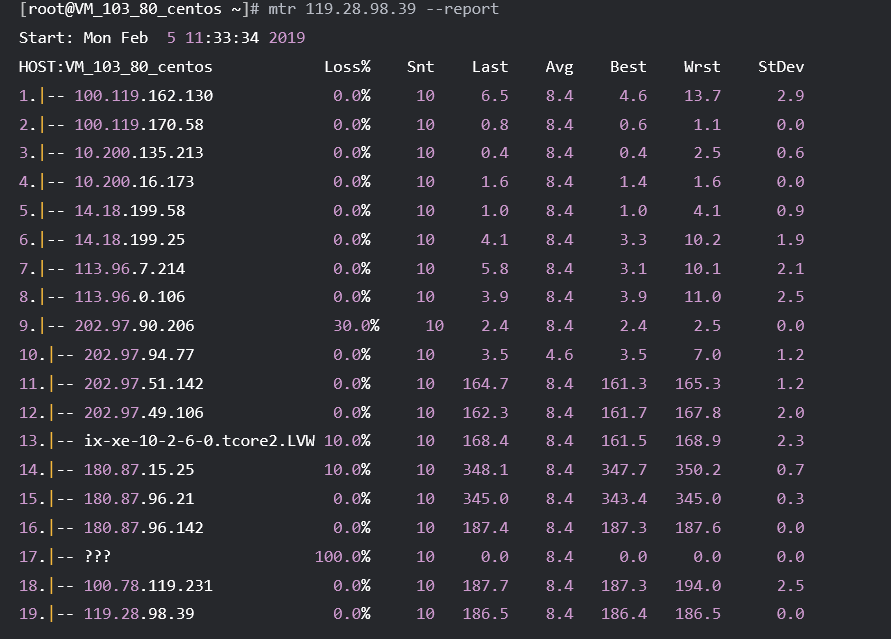
主要输出的信息如下:
HOST:节点的 IP 地址或域名。
Loss%:丢包率。
Snt:每秒发送的数据包的数量。
Last:最近一次的响应时间。
Avg:平均响应时间。
Best:最短的响应时间。
Wrst:最长的响应时间。
StDev:标准偏差,偏差值越高,说明各个数据包在该节点的响应时间相差越大。
说明
由于网络状况的非对称性,遇到本地到服务器的网络问题时,建议您收集双向的 MTR 数据(从本地到云服务器以及云服务器到本地)。
根据报告结果,查看目的服务器 IP 是否丢包。
如果目的地没有丢包,则表示网络正常。
如果目的地发生丢包,则执行 步骤2。
往上查看报告结果,定位第一次丢包的节点。
如果丢包发生在目的服务器,则可能是目的服务器的网络配置不当引起,请检查目的服务器的防火墙配置。
如果丢包开始于前三跳,一般为本地运营商网络问题,建议检查访问其他网址是否存在相同情况。如果存在相同情况,请反馈给您的运营商进行处理。如果有频繁丢包的情况,确实为网络不稳定的场景,则请 提交工单 进行咨询,并附上测试截图,以便工程师进行定位
Linux 云服务器在内存使用率未占满的情况下触发了 OOM(Out Of Memory)。如下图所示:

| 可能原因 | 处理措施 |
| 内存使用率过高 | 检查内存使用率是否过高 |
| 进程数超限 | 检查进程数是否超限 |
| 系统可用内存低于 min_free_kbytes 值 | 检查系统可用内存是否低于 min_free_kbytes 值 |
参见 内存使用率过高问题处理 ,查看实例是否内存使用率过高。若实例内存使用率正常,请 检查进程数是否超限。
参见 日志报错 fork:Cannot allocate memory,核实进程数是否超限。若总进程数未超限,则执行下一步。
登录云服务器,执行以下命令查看 min_free_kbytes 值。
sysctl -a | grep min_free
min_free_kbytes 值单位为 kbytes,下图所示 min_free_kbytes = 1024000 即为1GB。

执行以下命令,使用 VIM 编辑器打开 /etc/sysctl.conf 配置文件。
vim /etc/sysctl.conf
按 i 进入编辑模式,修改 vm.min_free_kbytes 配置项。若该配置项不存在,则直接在配置文件中增加即可。
说明
建议修改 vm.min_free_kbytes 值为不超过总内存的1%即可。
按 Esc 并输入 :wq 后,按 Enter 保存并退出 VIM 编辑器。
执行以下命令,使配置生效即可。
sysctl -p
可能是由系统可用内存低于 min_free_kbytes 值导致。
min_free_kbytes 值表示强制 Linux 系统最低保留的空闲内存(Kbytes),
如果系统可用内存低于设定的 min_free_kbytes 值,
则默认系统启动 oom-killer 或强制重启。具体行为由内核参数 vm.panic_on_oom 值决定:
若 vm.panic_on_oom=0,则系统会提示 OOM,并启动 oom-killer 杀掉占用最高内存的进程。
若 vm.panic_on_oom =1,则系统会自动重启。

每天两场(上午10:00,下午15:00),上云首选云服务器限量抢购,助力低成本上云
阿里云200+款云产品折上再折,满足多样场景的上云需求 活动规则